q principal component analysis
PCA is a pattern recognition algorithm that highlights similarities and differences in a dataset. It can also be used to optimally (least information loss) reduce the dimension (given by the number of variates) of a dataset by projecting the data (in the least squares sense) onto a few of its principal (high variability) components (dimensions in transformed space). A reduction to 2 components (best approximating plane) can be used to capture and visualize the majority of the variance in the dataset.
The components correspond to the new transformed basis and don’t necessarily have a one-to-one correspondence with the original variates; there are two ways to think about why we would consider dropping components in the transformed space:
- if certain variates are redundant (express almost the same information i.e. are highly correlated) then it makes sense to include only a single component to record the information contained in the variates
- by rotating and stretching the data into a new basis we are left with components along which there is very little variance; intuitively these components correspond to noise since they fail to record any essential information
Since we are comparing the spreads of variates it makes sense to standardize the data to have zero mean and unit standard deviation.
Given a dataset 
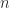
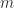
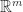

Next we calculate the scatter matrix as the product of the demeaned dataset (subtract the mean of each row from the row so that all the rows have mean zero) with a transposed version of itself: 


Since we are rotating our data into a new basis, what we will need is a measure of the variance of the data set projected onto each axis (infact any arbitrary axis since we need the one with highest variance). To illustrate how we can build such a measure (using only the scatter matrix and any arbitrary unit vector direction) let us project the data onto a line 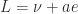



The distance of the projected point 


So the total variance or the squared sum of the distances of all the projected points from the center of mass is given by:
which after some matrix algebra works out to 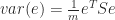

So now we can calculate the variance of the data projected onto some arbitrary direction 





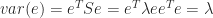

Note if the eigen-values are nearly the same then there is no preferable “principal” component. Also pca is optimal only in the least-squares sense.
Connection to SVD
The svd of the scatter matrix is 





Outline of PCA algorithm
- Calculate the scatter matrix S
- Calculate the SVD of
- Rearrange the singular values and singular vectors:
and
- Select a new basis as a subset of the singular vectors
- Project the data onto the new basis


.qml.mpca:{[x;r] \x is samples (rows) by variates (cols)
t:-[;avg x] each x;
t: t $ flip t;
s:.qml.msvd[t];
u:s[0][;1+til r];
:flip[u] $ x;
};
m:10;
n:800;
x:(m;n)#(m*n)?1f;
.qml.mpca[x;2]
Kernel PCA
Is an extension of PCA for non-linear distributions. We would like to apply PCA in a higher dimensional space 
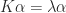



Variance Connection, Karhunen Connection
A typical data matrix contains signals each of which has some underlying noise; a reduced rank SVD approximation of the data matrix captures a highest variance mixture of the original signals in a lower dimensional space. The noise is usually associated with the smallest singular values (outliers generally have the least to say about the true distribution of the data because well it is noise and doesn’t belong in the dataset; they have the smallest semi-axis in the transformed unit sphere i.e. they are what the fuck can i explain this better?) which are dropped to form the approximation.
the karhunen–loève representation of a stochastic process
Consider a continuous time, continuous state space stochastic process 

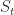

Assume the stochastic process is centered (each random variable is centered) so that 
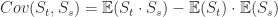

Let us assume that this kernel is positive, symmetric and square integrable 
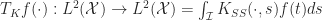
is positive, self-adjoint and compact. It therefore follows from the Spectral Decomposition Theorem that 
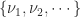
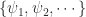
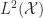
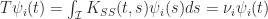
The integral transformation 

Let us make a stronger assumption (than being square integrable) that the covariance (kernel) function is continuous 
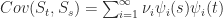
where convergence is absolute and uniform in both variables. We define a new set of random variables 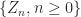

that are orthogonal and centered 
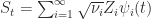
where convergence is uniform over the index set
References:
1. Karhunen-Loeve Expansion of Vector Random Processes
2. Large Scale Learning: Dimensionality Reduction
singular value decomposition
The singular value decomposition of a 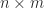
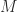

where the rows or right-singular vectors of 
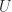
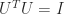
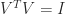
The singular value matrix 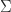

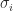
As a geometric transform
Any real matrix maybe viewed as a geometric transformation

that when applied to a set of data points 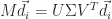


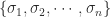
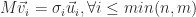
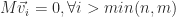
As a linear combination
Another way to see this factorization is as a weighted ordered sum of separable matrices 
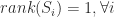
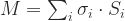
As an unconstrained optimization
We can also formulate the solution of the svd in terms of an optimization: find the best (minimizes the frobenius norm 
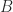


This result is the Eckhart-Young theorem.
Condition Number
The condition number of a matrix can be given in terms of its singular values:

A matrix is said to be ill conditioned if the condition number is too large. How large the condition number can be, before the matrix is ill conditioned, is determined by the machine precision.

10 comments